
Committing to dates is the classic P.I.T.A. of managing things containing an unknown amount of unknowns. The main point of Agile is acknowledging that we don’t really know the problems until we engage them. How, then, do we reconcile the need to forecast dates for all those depending on us?
Let’s start from one foundational statement I presented in my post about Poker and Product Management:
Humans suck at estimating complex work. They just suck at it remarkably consistently.
This is accentuated when the work includes a high amount of problem solving and unknowns. New unforeseeable problems cropping up, environments shifting, dependencies on others or just plain learning more about the nature of the problem at hand.
The classic solution has been putting more effort in on the front end: “Measure twice, cut once”.
Then as things go out of whack, the people involved in planning get blamed for not having foreseen every single scenario. Or worse yet, the people executing get blamed for not being able to deliver on a made-up date that someone invented before we even really knew the full scope of delivering the expected outcome.
Try to remember a project you’ve worked on (more complex than mowing your lawn or cooking dinner) where the scope didn’t change. Could thorough pre-planning really significantly have cut that risk down?
Ok, we get it, dates are hard. But what’s the option? Fall into complacency and just assume an “it’s ready when it’s ready” attitude? Or keep on inventing dates and backing into them, sacrificing sanity and quality as we do so?

Consistency and Statistics to the Rescue!
The key to success is the “…they just suck at it remarkably consistently” part.
Where there’s consistency, there’s a chance for statistics to shine. ❤️Math ❤️!
Consistent things tend to trend in predictable ways over a long enough period of time and that is also true for estimates on the relative size of a piece of work.
The only problem with consistency and statistics is that they require longevity and patience. Even with a predictable distribution of values in the long run, a small sampling can have really high volatility. A task someone thought to take a few days can run on for weeks, and something that was supposed to be a nightmare to implement suddenly magically falls into place in a few lines of code.
But viewed at a long enough timespan things start magically lining up.
Dates as an Output
The secret to effective date management is leveraging that consistency to derive dates as a function of past estimation-based velocity and future estimations.
When you approach dates as an input, you engage with the squad or some know-it-all manager and get answers like “yeah, I think that can be done in 3 sprints, so it’ll be delivered on date x”.
To get dates as an output, all you need to do is diligently track the pace at which the squad chews through previously estimated items and make sure the rest of the backlog stays estimated at a sufficient level of precision. You never discuss dates or specific times required to build an item. Those come out of the data provided automatically.
When you do all this right, any change in priorities, any unexpected delay in another deliverable, or an unexpected vacation of a squad member will automatically cascade into future delivery dates without the need to recalculate. Automatically. 🎇 MAGIC 🎆
Prove it, Bub!
Let’s look at an example I’ve conveniently put together.
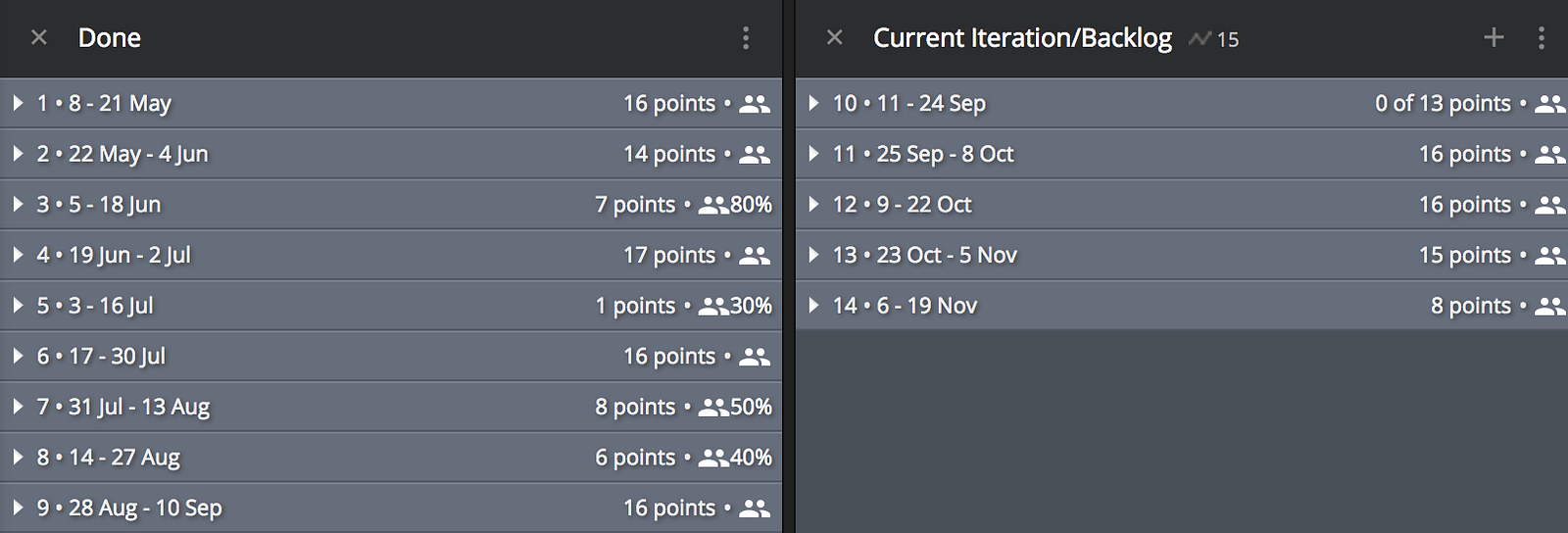
In the picture above is my example project that I’ve pretended to be working on since May. All the sprints are collapsed, so all you can see is a few things:
- Dates of the sprints — I’ve got them set at 2 weeks and my project start date is May 8th.
- The amount of story points I’ve completed in each past sprint or am projected to complete in future sprints.
- The focus factor of each past and future sprint. This is a really critical piece of the puzzle. The focus factor is calculated by your available capacity divide by your optimal capacity in a sprint. If you’ve got a 5 person squad and 1 person is on vacation for 1 week in a 2 week sprint, your FF would be 90% for that sprint. If your velocity in that sprint is 40, it would get calculated as 44 when calculating your average velocity. Conversely, if your average velocity is 40 and you’ve got a sprint spanning Christmas coming up, so your projected FF is 30%, you’d only be allowed to forecast 12 points for that sprint.
These are the main building blocks you’ll need to predict the future.
As long as all future work is properly estimated adhering to a cone of uncertainty rule (the further down a backlog things are, the more vague they should be allowed to be), you should have really accurate visibility into the future.
Wait, Why is There Only 1 Point in Sprint #5?!
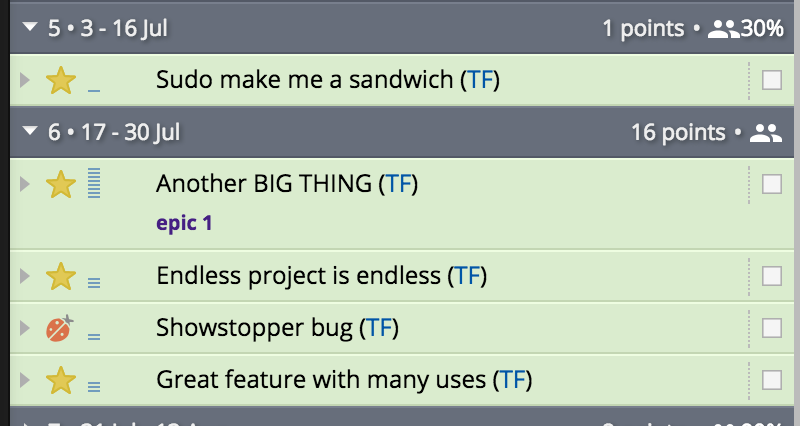
The more observant may have noticed some weird data in there. One of them being the horrible nightmare of sprint #5. What happened?! Sure, that sprint was clearly a wash in capacity as the focus factor was 30%, but just 1 point? That makes no sense.
Upon closer inspection we’ll notice that it was just the PO sucking and bringing in work that wasn’t properly chopped into smaller chunks.
The story titled “Another BIG THING” is 8 story points. It’s quite obvious that the story was started, and a huge chunk of it completed, in the previous sprint, but the story spilled over to sprint #6.
While this isn’t awesome, it’s nothing to be afraid of. Estimates are meant to suck in the short term. But when you look at the averages of sprints 4–6 and account for their focus factors, they actually fall quite nicely in line with expectations.
The Future 🔮
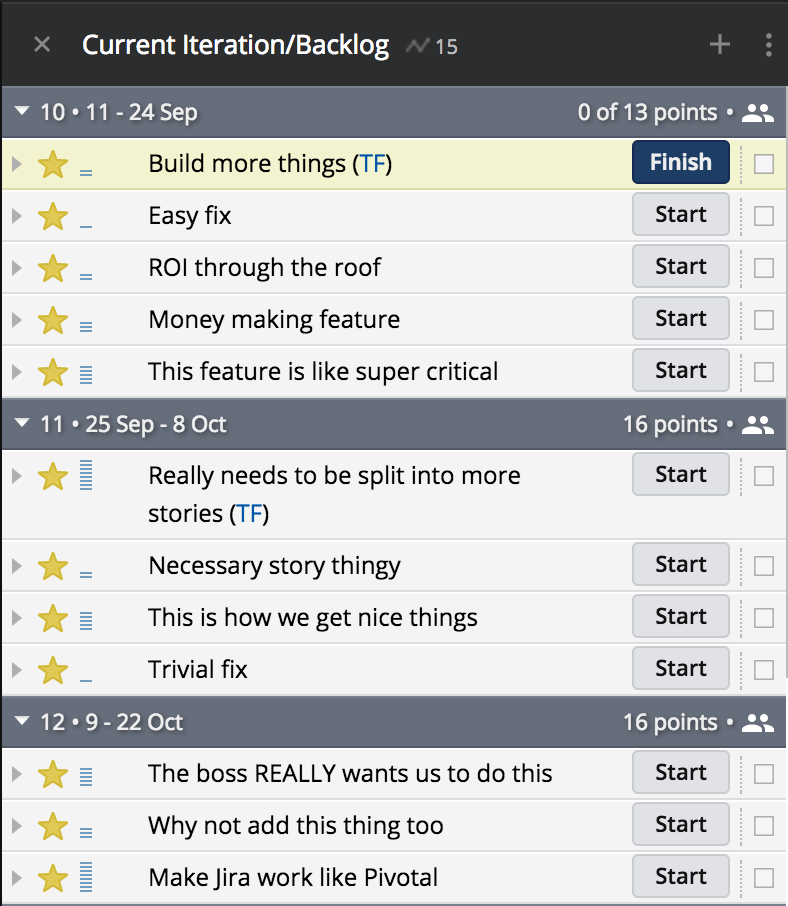
Now here’s where things get really sexy!
All I need to do as a Product Owner, is maintain a linear priority on my backlog and make sure the team has a story point level estimate on everything.
When that is done, everything pertaining to dates is handled automatically.
I have not assigned stories to sprints. They are assigned in priority order, based on what my squad can work through according our current understanding of their velocity, adjusted for focus factor for each sprint.
So, when the big bossman who wants to know the status of the story “The boss REALLY wants us to do this”, I can say immediately it’s scheduled for an Oct 22nd delivery. As long as nothing changes…
Accommodating Change
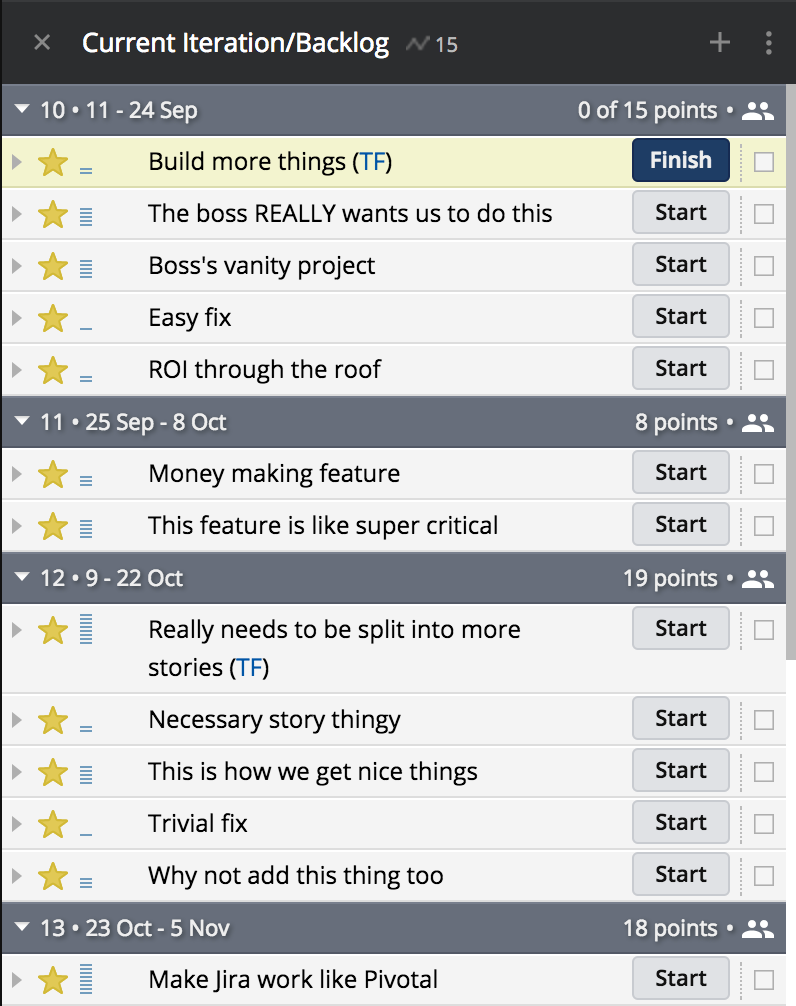
…but as we know, things always change.
Not only was the big dog not happy with when his thing was to be delivered, and promptly ordered it to the top of the backlog, he also decided to complete his swooping with a surprising new 5-pointer (“Boss’s vanity project”), also scheduled for an “As ASAP as possible” delivery.
Ok, that’s not cool, but that’s what happens sometimes. The change in direction could’ve just as well come in the form of a surprising critical bug in production or an unexpected discovery. Change is change. It happens. All of the time.
What’s awesome now is that instead of just absorbing the hit, we get immediate clarity into the future too. Before the change, we were slated to deliver the task of “Make Jira work like Pivotal” on Oct 22nd, but due to the changes, it’s now clearly pushed into sprint #13, to be completed on Nov 5th.
We can automatically notify whichever stakeholder is interested in that story on the current state of affairs. If that’s not acceptable, we can reprioritize that story higher, but that will invariably push something else down. You can’t cheat the system. If you have too much on your plate compared to expectations, you will see that flagged immediately.
As long as you stay consistent by diligently tracking velocity, accounting for focus factors and keeping your backlog sufficiently populated, prioritized and estimated, you get all the tools you need to see the future — even when it suddenly changes!
Bonus: Example in Video Format!
Caveats
As always, these practices come with a number of warnings. It’s just like buying a mogwai: Life with it is amazing as long as you don’t screw it up by breaking or bending the rules.

1. Don’t Re-estimate!
One classic faux-pas is teams re-estimating work done based on what actually happened or based on how much work is left when a story spills over from sprint-to-sprint. Don’t. Just… no!
This ruins the whole point of the system relying not on tracking work done, but tracking the amount of error in future-looking estimates. If stuff in the past reflects actuals and stuff in the future reflects estimates, they will have very limited correlation.
Once a story is being worked on, you don’t touch its estimate.
2. Allocate Time for Estimating
It’s critical that estimates come from the actual squad, not some know-it-all tech manager, or worst of all, the PO.
Make sure the squad takes its time weekly to dive into the depths of the backlog, talk about stories, get context from the PO, give points — even if it’s early and vague sleeve estimates. Just because things shouldn’t be re-pointed after the fact, doesn’t mean you can’t adjust points upon further grooming as details start shaping out.
Also, don’t be shy about using high-pointed placeholders deep in the depths of the backlog. Having vague placeholders is better than a deceptively shallow backlog.
3. Stay Consistent
Whatever you do and however you choose to run the show, just make sure you’re consistent. Changing squad members, adjusting practices, and any other tweaks usually toss you right back to square 1. Make changes really conservatively and carefully. It takes multiple sprints to recalibrate a changed team.
4. Be OK with Occasional Errors
There’s no long term long enough to completely remove volatility from these values. At times, estimates derived with this method might be off — way off. The key is that over time they’ll trend to correctness way more often than not.
At least way more than using conventional methods.
5. Never EVER Benchmark Velocities
If anyone tries to use velocities as a value to gauge the quality of a squad, or worse yet, benchmark against another squad, please tell them to reconsider their life and choices.
A squad’s estimates are subjective and abstract by design and reflect the collective estimation bias of the squad. It has nothing to do with the quality or productivity of their work.
You can’t really even derive real insight from the evolution of a squad’s velocity over time. It’s perfectly normal for a squad to get much better at estimating their work, leading to a shift in values.
It’s equally commonplace for a story point inflation to take place, leading to the squad’s velocity to rise. This doesn’t mean they got better, unfortunately.
Prerequisites
Here’s the fine print: For all of this to work, you need to establish a few ground rules.
To make your “dates as an output” magic a reality, please make sure you adhere get these things set up properly:
1. Squads that Stay Together
Every person fails at estimates in a different way and as you change a squad’s structure, you include a high amount of uncertainty in how the squad’s work estimations evolve.
The best way to make a squad’s forecasts useless is to randomly change people in or out. It takes several weeks for a squad to properly go back to business as usual after a change.
2. Tooling
A lot of the necessary things here require a whole bunch of automation that inferior tools don’t offer. Managing things like historical velocity, calculating current average velocity (adjusted for focus factors), forecasting how the backlog slots into future sprints, and adjusting for future sprints with limited capacity are things that when left for humans to do, end up not being done — and most of the value of the whole process flies out the window.
I personally love the way Pivotal Tracker does this and that’s the service I’ve used for the example above. But I’m sure there’s plenty of other tools out there that are able to help as well.
I also claim that using Jira for this is a fast track to failure. If you feel you can prove me wrong, please get in touch, but I’ve yet to see it done.
3. Embrace the Abstract
Story points are great, but as they are numeric, they have a really big allure for some people to start thinking in terms of real world measures. “A story point is like a day of work, right?” is the classic tell tale sign of a person for whom “Scrum” just means daily stand-ups and stuff.
Never entertain conversations that try to match story points with real world measured. They are numeric simply so we can do math on them.
Always keep the conversation along the lines of “story X is bigger than story Y which is about the same size as story Z”.
4. Collective Buy-in
This whole thing is a garbage-in-garbage-out system. If Product Owners don’t put in the time to define stories, squads don’t take time to groom their backlogs and velocities / focus factors don’t get accounted for, none of this matters.
Put in the time to get the data points in and you will be rewarded by never having to worry about date management ever again.
5. Scale
Here’s the bad news for tiny squads: while you can theoretically get this to work with a few people, for best values, I’d recommend having squads at around 5–9 members in size.
Only at that scale you start truly harnessing the predictability.

When you truly master this method of date management, you’re mere steps away from treating roadmaps as forecasts instead of contracts.
You still will be faced with internal stakeholders that require hard dates and inflexible delivery plans. If they can’t be shown the light of why that’s an impossible ask in environments of high uncertainty, at least you get the tools to communicate early when things are going down the 🚽 — and you have significantly better tools to explain what led to this.
…and as noted before, that’s the best outcome of Agile: being able to stay one step ahead of change.



